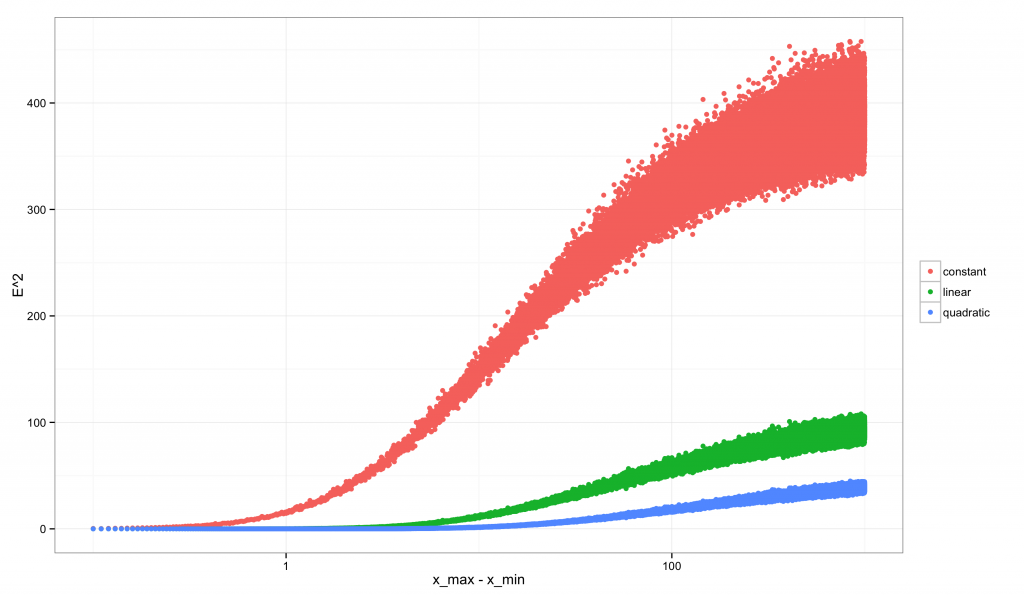
Hilbert空间特点是通过定义内积$ < \cdot , \cdot > $来导出范数,进而导出距离函数。由内积可以定义正交关系,即若$ <x,y>=0 $则定义$ x , y $在空间中正交。一列彼此正交的元素$ e_j $称为一组正交基,内积的概念给出了任意元素$ x $相对于这组正交基的坐标,即元素$ x $在各个正交基上的投影$ < x , e_j > $.
最常见的Hilbert空间是Euclidean空间$ R^n $,即是线性代数研究的范畴。平面几何研究的是$ R^2 $,“勾股定理”反映的性质就是属于这个空间内的。“勾股定理”用Hilbert空间中的概念表达即为:
给定$ R^2 $中的一组标准正交基${e_1 , e_2} $,则任意点$ x $关于0元素的距离$ \parallel x \parallel $满足:$ \parallel x \parallel^2=\mid<x , e_1>\mid^2 + \mid <x , e_2>\mid^2 $.
4.联接方式:广义线性模型里采用的联连函数(link function)理论上可以是任意的,而不再局限于$f(x)=x$。当然了联接函数的选取必然地必须适应于具体的研究案例。同时存在着与假设2.1里提及的分布一一对应的联接函数称为标准联接函数(canonical link or standard link),如正态分布对应于恒等式,泊松分布对应于自然对数函数等。标准联接函数的推导及其应用上的优点涉及到指数分散族的标准化定义,这里不做详述。
这里$\Psi$和$\theta$是实参数,$b(.)$和$c(.;.)$是实函数,该密度函数的支集(support)$D_{\Psi}$是$R$的子集,且不依赖于$\theta$。满足$\theta=\eta=g(\mu)$的联接函数$g(\mu)$称为标准联接函数(standard or canonical link)。
一般情况下参数$\Psi$的值是未知常数(fixed and unknown),因此在许多GLM文献里指数分布族又被称为单参数指数族(one-parameter exponential family)。对于比较常用的分布,$\Psi$和$\theta$的取值具有特殊的形式:
再结合观测值之间的独立性,全体观测值的对数似然函数可记做:$\sum_i logL({\theta}_i,\phi;y_i)$
一般情况下最大化上述的对数似然函数很难找到解析解(正态分布是特例之一),因而必须使用数值方法求解。McCullagh和Nelder(1989)证明了使用Newton-Raphson方法,结合Fisher scoring算法,上述对数似然函数的最大化等价于连续迭代的加权最小二乘法(iteratively weighted least squares, or IRWLS)。
相反的一个极端情况就是,所有自变量$x_i$的每一个观测值或称为数据的样本点(data points)对于响应变量$Y$都有影响,这样的模型称为全模型(full or saturated model)。一般可以通过构造阶数足够高的多项式或者把所有的量化观测值(quantitative)视为质化观测值(qualitive),并且引入适当数量的交叉项(interactions)来构造全模型。
广义线性模型的假设检验可以分为两种:一是检验目标模型相对于数据或预测值的拟合有效性的检验(goodness of fit test);另外一种则是对“大”模型以及对“大”模型的参数施加一定的线性约束(linear restrictions)之后得到的“小”模型之间的拟合优度比较检验。直观上的理解就是,“大”模型具有更多的参数,即从参数的线性约束总可把一个或多个参数用其他参数的线性组合来表示,然后代入“大”模型,从而参数的个数减少,派生出所谓的“小”模型,也就是说“大”和“小”并非任意的,而是具有一种派生关系(nested models)。如果把全模型认为是“大”模型,而目标模型是“小”模型,那么上述两种检验的本质是相同的。因而假设检验的零假设(null hypothsis)可以统一且直观地设定为:“小”模型(目标模型)是正确的模型。
lasso estimate的提出是Tibshirani在1996年JRSSB上的一篇文章Regression shrinkage and selection via lasso。所谓lasso,其全称是least absolute shrinkage and selection operator。其想法可以用如下的最优化问题来表述:
继续前两篇博文中对于最小角回归(LARS)和lasso的介绍。在这篇文章中,我打算介绍一下分组最小角回归算法(Group LARS)。本文的主要观点均来自Ming Yuan和Yi Lin二人2006合作发表在JRSSB上的论文Model selection and estimation in regression with grouped variables.
set.seed(123);
n = 5000000;
p = 5;
x = matrix(rnorm(n * p), n, p);
x = cbind(1, x);
bet = c(2, rep(1, p));
y = c(x %*% bet) + rnorm(n);
如果用内置的 lm 函数对 x 和 y 进行回归分析,就有可能出现如下错误(当然,也有可能因为内存足够而运行成功):
> lm(y ~ 0 + x);
Error: cannot allocate vector of size 19.1 Mb
In addition: Warning messages:
1: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
Reached total allocation of 1956Mb: see help(memory.size)
2: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
Reached total allocation of 1956Mb: see help(memory.size)
3: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
Reached total allocation of 1956Mb: see help(memory.size)
4: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
Reached total allocation of 1956Mb: see help(memory.size)
gc();
dat = as.data.frame(x);
rm(x);
gc();
dat$y = y;
rm(y);
gc();
colnames(dat) = c(paste("x", 0:p, sep = ""), "y");
gc();
# Will also load the DBI package
library(RSQLite);
# Using the SQLite database driver
m = dbDriver("SQLite");
# The name of the database file
dbfile = "regression.db";
# Create a connection to the database
con = dbConnect(m, dbname = dbfile);
# Write the data in R into database
if(dbExistsTable(con, "regdata")) dbRemoveTable(con, "regdata");
dbWriteTable(con, "regdata", dat, row.names = FALSE);
# Close the connection
dbDisconnect(con);
# Garbage collection
rm(dat);
gc();
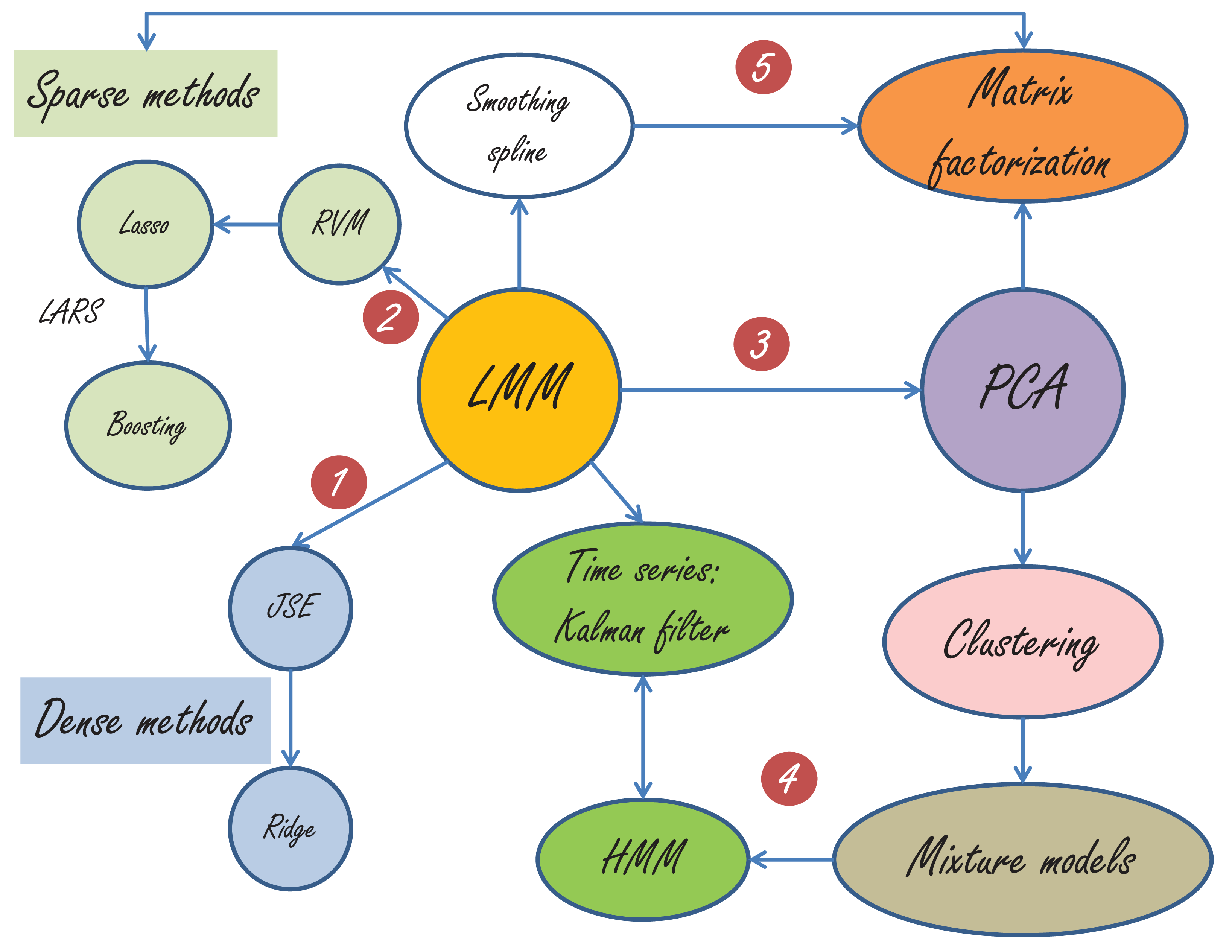
好了,是时候停止卖萌,进入主题了。LMM全称是Linear Mixed Model(混合线性模型)。她血统高贵,与现代统计学之父Ronald Fisher提出的随机效应一脉相承。上个世纪50 年代,Charles Henderson 为她打造了国际一流的统计性质(BLUE and BLUP),他的学生Shayle Searle 更是为她配上了“黑客帝国(Matrix)” 的装备,从此她的名字将永远记入统计学的史册。1991年,statistical science上有一篇很经典的文章“That BLUP is a Good Thing: The Estimation of Random Effects”,里面谈到了她许多超一流的品质。事实上,我们在实践中已经用到了她的很多好的性质,只不过我们以前不知道罢了。
第三,LMM与PCA(Principal Component Analysis)的联系似乎不是那么直接,因为这里已经从监督学习走向了非监督学习。然而,当PCA被赋予概率的解释后,天堑变通途。这篇里程碑式的文章就是Probabilistic principal component analysis by Tipping and Bishop。PCA与clustering的亲密关系暴露在本世纪初,clustering和mixture models的关系嘛,应该是不言而喻的。
第四,大家都知道,Mixture models里面是有一个隐状态,比如在做clustering的时候,这个隐状态就用来表明数据点与cluster的隶属关系。当这些隐状态不再是独立等分布的时候,比如,后一个状态取决于前一个状态的时候,HMM便应运而生。HMM与卡曼滤波(Kalman filter)基本上可以看做孪生兄弟,一个为离散状态而生,一个为连续状态而来。LMM与卡曼滤波的关系在“BLUP is a good thing”这篇雄文中早有讨论。当年学控制的我与卡曼滤波有过初步接触,但是却与LMM 失之交臂,还好在耶鲁与LMM再续前缘。
面对如此波澜壮阔的模型表演,不知道大家会如何感想?这里我先引用Terry Speed在“BLUP is a good thing”的评论里的最后一段话:“In closing these few remarks, I cannot resist paraphrasing I.J. Good’s memorable aphorism: `To a Bayesian, all things are Bayesian.’ How does `To a non-Bayesian, all things are BLUPs’ sound as a summary of this fine paper?” 大师的话值得久久回味……我自己总结的话,来点通俗易懂的,还是这句“天下武功,若说邪的,那是各有各的邪法,若说正的,则都有一种‘天下武功出少林’的感觉”。
如果回到工程实践的话,或许我们应该追问:“为什么引入随机效应后会有如此神奇的疗效?”Efron教授在他的一篇文章中称赞James-Stein Estimator:“This is the single most striking result of post-World War II statistical theory”。 我想,我们应该可以从JSE 中寻找到一些蛛丝马迹。JSE的原问题是:现已观察到$N$个$z$值,即$[z_1,z_2,\dots,z_N]$,还知道$z_i$独立地来自以$\mu_i$为均值,方差为1的正态分布,即$z_i|\mu_i \sim \mathcal{N}(\mu_i,1)$, $i=1,2,\dots,N$.问题是:如何从观察到的$\mathbf{z}=[z_1,z_2,\dots,z_N]$估计$\boldsymbol{\mu}=[\mu_1,\mu_2,\dots,\mu_N]$?最大似然法和James-Stein Estimator给出解答分别是(更多细节参考《那些年,我们一起追的EB》):
如前所说,CG 的一大优势在于编程实现非常简单。不依赖于任何附加包,我们就可以用几十行 R 代码搞定其核心算法。
## Target: solve linear equation Ax = b. A is positive definite
## Ax -- A function to calculate the matrix-vector product
## `A * x` given a vector `x` as the first argument
## b -- Vector of the right hand side of the equation
## x0 -- Initial guess of the solution
## eps -- Precision parameter
## verbose -- Whether to print out iteration information
cg = function(Ax, b, x0 = rep(0, length(b)), eps = 1e-6,
verbose = TRUE, ...)
{
m = length(b)
x = x0
r = b - Ax(x0, ...)
p = r
r2 = sum(r^2)
for(i in 1:m)
{
Ap = Ax(p, ...)
alpha = r2 / sum(p * Ap)
x = x + alpha * p
r = r - alpha * Ap
r2_new = sum(r^2)
err = sqrt(r2_new)
if(verbose)
cat(sprintf("Iteration %d, err = %.8f\n", i, err))
if(err < eps)
break;
beta = r2_new / r2
p = r + beta * p
r2 = r2_new
}
x
}

")
")
")